Multi-label Classification Problems with Large Langage Models

In today's data-driven world, accurately categorizing information has become crucial. The task of multi-label classification, where data can belong to multiple categories simultaneously, addresses this need effectively. Unlike traditional single-label classification, multi-label classification mirrors the complexity of real-world data and often comes to the forefront in wider data analysis efforts. This problem is particularly critical in areas such as social media tagging, news organization, disease diagnosis, and product recommendation. It becomes especially challenging in text analysis, where a single span of text can reference multiple notions in nuanced ways.
While traditional Natural Language Processing (NLP) techniques have been highly effective for many tasks, they often require substantial domain knowledge and manual feature engineering. Advances in deep learning and the emergence of Large Language Models (LLMs) have shifted the landscape, offering more powerful and automated solutions for complex NLP problems, as well as a more precise and insightful approach to text analysis.
TL;DR
Multi-label classification, crucial for tasks like social media tagging, is greatly enhanced by LLMs. These models automate the handling of complex, real-world data, making them ideal when traditional model training is too complex. With user-friendly APIs, LLMs offer cost-effective, high-performance solutions for text analysis. Techniques like few-shot prompting and chain of thought further improve their accuracy. Regular monitoring and evaluation ensure these models stay effective in production.
A quick note on Multi Label Classification
In multi-label classification, unlike multi-class classification where each instance is assigned to exactly one out of many classes, each instance can be assigned to zero, one, or more classes. This means that each class label is not mutually exclusive, and the number of labels per instance isn't fixed. Indeed, each instance in the dataset can have one or more labels assigned to it, or potentially none at all. As such, there can be relationships or dependencies among the labels, meaning the presence of one label might influence the presence of another.
These labels can be represented in various ways:
- One column per category containing binary indicators (0 or 1) showing whether the label is applicable to the document ;
- A list of labels associated with the text content, stored in a single column.
| ID | Content | Labels | Politics | Economy | Sports | Entertainment |
|---|---|---|---|---|---|---|
| 1 | "Government passes new healthcare reform." | ["Politics"] | 1 | 0 | 0 | 0 |
| 2 | "Stock market hits new highs amid economic boom." | ["Economy"] | 0 | 1 | 0 | 0 |
| 3 | "Celebrity singer releases new music video." | ["Entertainment"] | 0 | 0 | 0 | 1 |
| 4 | "Local sports team wins championship game." | ["Sports"] | 0 | 0 | 1 | 0 |
| 5 | "Election debate highlights key economic policies." | ["Politics", "Economy"] | 1 | 1 | 0 | 0 |
| 6 | "AI will take on the world” | [ ] | 0 | 0 | 0 | 0 |
This type of problem is particularly challenging because as the number of possible labels increases, the label matrix becomes more sparse. This means there may be very few examples for many label combinations, making it difficult for models to learn effectively. Typically, a large amount of data is required for model training in such cases.
But what should you do when you don’t have the data to tackle multi labels classification problems in a text setting or you don't have the resources to build it ?
Why Should You Choose LLMs Over Traditional NLP Techniques for Text Analysis?
Traditionally, NLP project involve multiple phases, such as:
- Preprocessing: converting all text to lowercase, removing punctuation, special characters and numbers, reducing words to their base form through stemming or lemmatization
- Feature Extraction: using Bag of Words or N-grams techniques
- Model Selection and Hyper Parameter tuning
The specific case of multi label classification always comes with a set of challenges, the two main ones being:
- Label Imbalance: Some labels might appear very frequently in the dataset, while others are rare. Usually the more imbalanced is the data, the more difficult will be the model training.
- Correlation Among Labels: The inter-dependency between labels can complicate the modeling process, as the predictive model must effectively learn these dependencies.
From pre-processing to model validation, this process can take a lot of time and resources.
Luckily, we live in a world where pre-trained specialized language models are readily available. Additionally, providers offer access to large generalist models trained on massive amounts of text, known as Large Language Models (LLMs). Large Language Models are ideal for text analysis due to their ability to understand and generate human-like text. They can efficiently handle a wide range of tasks such as summarization, sentiment analysis and language translation in most languages. Their training on vast datasets allows them to recognize patterns and nuances in text, making them versatile and powerful tools for extracting insights and automating language-related tasks.
Why should you choose an LLM for text analysis ?
- Easy to use: LLMs are ready to use and do not require in-depth coding skills or extensive knowledge of data science and machine learning. Providers offer user-friendly APIs, making it simple to integrate LLMs into your applications, regardless of the programming language you use. Despite being a relatively recent technology in the mainstream, comprehensive documentation, tutorials, and community support are available to help users get started quickly. In most cases, the text does not even have to be preprocessed.
- Cost Considerations: Deploying a language model can be cost-intensive, especially if you don't already have access to a GPU. Nowadays, the best models for any language-related task have a neural network architecture. Using GPUs for running language models in production ensures efficient operation, delivering high performance and quick responses. However, setting up a GPU-equipped instance, whether in the cloud or on-premises, can significantly increase deployment and exploitation costs. For performing tasks on small text spans, considering the use of LLM providers' inference services can be more cost-effective because they charge per token (a sub-portion of a word).
- Performance: LLMs perform very well in most cases. Interestingly, the output of the model can be adjusted easily by providing it with one or more examples which will increase the quality of predictions.
It's often mentioned that LLMs are not deterministic, meaning the same query can produce different responses. While this is true, for simple tasks like classification, it is very unlikely to get different answers. Additionally, providers like OpenAI offer a seed parameter to achieve mostly deterministic results by imposing the random factor value.
Choosing to use an LLM over traditional NLP techniques can significantly speed up the development process for any text analysis task.
However, you will still need a test dataset to evaluate how well your solution performs in your specific use case. For multi-label classification tasks, a good testing dataset should reflect the complexity of your use case. Each sample should follow a consistent format, and the dataset should have a balanced distribution of label combinations, including samples with no label. If you know the real-world distribution of the labels, aim to match your test dataset to it. Generally, your test dataset should contain at least a few hundred samples, but the more labels you have, the larger your dataset needs to be. Ideally, the more the better.
Regularly generating test cases with fresh data should be a standard practice, as this enables you to monitor the model's performance in real-world conditions using real-life data.
Production challenges
Quality of Predictions and Monitoring
Classification is a crucial aspect of data analysis and strategic decision-making, demanding high-quality predictions to be effective. To evaluate the quality of predictions, there are numerous metrics available, each focusing on different aspects of performance (see annexe on classification metrics). For example, a metric such as Precision Score helps determine how well the classifier performs at prioritizing true positives over false negatives.
In production environments, tracking the outcome of each model call is vital. Storing the input and output traces enables post-analysis, helping identify accurate and inaccurate predictions. This trace analysis helps in developing strategies to enhance prediction quality and provides insights into token usage and call duration. To visualize the stored traces, you could use tools like LangSmith or Phoenix which provide tools to monitor LLM applications. Note that longer token sequences can lead to increased generation time, which should be considered when optimizing performance. Continuous evaluation of the model's performance with fresh data is also essential. Regular assessments ensure that the model remains relevant and accurate over time. This can be done through manual reviews or by employing another LLM to evaluate the classifier's output, a strategy known as LLM as a judge. This method helps in maintaining the model's efficacy by integrating real-world feedback.
Additionally, refining the model involves experimenting with different prompts to eventually improve results. When testing various prompts, it's important to store each prompt template along with its corresponding classification report. This allows for a thorough comparison based on chosen metrics to determine which prompt yields the best results.
An example of multi-label classification Report
import numpy as np
import pandas as pd
from sklearn.metrics import accuracy_score, classification_report, hamming_loss, zero_one_loss, jaccard_score, precision_recall_fscore_support, multilabel_confusion_matrix
from sklearn.preprocessing import MultiLabelBinarizer
def get_scores(labels_true: pd.Series, labels_pred: pd.Series, labels: list[str] = [], verbose=False) -> dict[float | dict[float]]:
mlb = MultiLabelBinarizer()
if len(labels) == 0:
labels_true_binary = mlb.fit_transform(labels_true)
else:
_ = mlb.fit([labels])
labels_true_binary = mlb.transform(labels_true)
labels_pred_binary = mlb.transform(labels_pred)
subset_accuracy_score = accuracy_score(labels_true_binary, labels_pred_binary)
ham_loss = hamming_loss(labels_true_binary, labels_pred_binary)
multilabel_zero_one_loss = zero_one_loss(labels_true_binary, labels_pred_binary)
report = classification_report(
labels_true_binary, labels_pred_binary,
zero_division=np.nan,
output_dict=True,
target_names=mlb.classes_
)
jaccard_micro = jaccard_score(labels_true_binary, labels_pred_binary, average='micro', zero_division="warn")
jaccard_macro = jaccard_score(labels_true_binary, labels_pred_binary, average='macro', zero_division="warn")
jaccard_weighted = jaccard_score(labels_true_binary, labels_pred_binary, average='weighted', zero_division="warn")
jaccard_samples = jaccard_score(labels_true_binary, labels_pred_binary, average='samples', zero_division="warn")
label_wise_jaccard = jaccard_score(labels_true_binary, labels_pred_binary, average=None, zero_division="warn")
report['weighted avg'].update({'jaccard score': jaccard_weighted})
report['micro avg'].update({'jaccard score': jaccard_micro})
report['macro avg'].update({'jaccard score': jaccard_macro})
report['samples avg'].update({'jaccard score': jaccard_samples})
for i, label in enumerate(mlb.classes_):
report[label].update({'jaccard score': label_wise_jaccard[i]})
if verbose:
print(f"""
Accuracy Score: { subset_accuracy_score }
Zero One Loss: { multilabel_zero_one_loss }
Hamming Loss: { ham_loss }
# =================================================================== #
{ pd.DataFrame(report).T }
# =================================================================== #
""")
return {
'accuracy_score': subset_accuracy_score,
'zero_one_loss': multilabel_zero_one_loss,
'hamming_loss': ham_loss,
'report': report
}
MultiLabelBinarizer() is used to convert the multi-label data into a binary format suitable for evaluation metrics.
Several metrics are used to evaluate the model's performance, see definition in annexe. classification_report computes precision, recall, f1-score and support at the same time, for each label and in average.
If this function is called in verbose mode, it displays a comprehensive multi label classification report. It always return the report structured as a dictionary.
By systematically evaluating performance, experimenting with prompts, and analyzing outcomes, you can continuously improve the classification process and ensure its effectiveness in real-world applications.
Price, Time, Quality trade-off
Since LLMs entered the mainstream, various techniques have been developed to address specific problems and improve prediction quality. Notable methods include few-shot prompting, chain of thought, and tree of thoughts, with new techniques emerging frequently. Each method uses different numbers of tokens in the input and output, impacting performance, speed, and applicability. Providers typically allocate 1/4 of costs to input tokens and 3/4 to output tokens. Understanding token distribution is crucial for managing costs and latency: it is essential to select the appropriate technique based on your budget and requirements, considering that more tokens lead to higher costs and longer execution times.
Techniques like chain of thought and tree of thoughts encourage the LLM to "think" more deeply. While these methods excel in performance for simple and complex problems, they are also more costly and time-consuming due to increased token usage. Chain of thought involves the LLM generating a step-by-step explanation of the final result. Tree of thoughts involves multiple "specialists" debating and presenting arguments to reach a final answer. Both techniques generate a substantial number of output tokens, leading to higher costs.
Example of Chain of Thoughts
I went to the market and bought 10 apples. I gave 2 apples to the neighbor and 2 to the repairman. I then went and bought 5 more apples and ate 1. How many apples did I remain with?
Let's think step by step.
Example of Tree of Thoughts
Imagine three different experts are answering this question.
All experts will write down 1 step of their thinking,
then share it with the group.
Then all experts will go on to the next step, etc.
If any expert realizes they're wrong at any point then they leave.
The question is: If I bought 10 apples, gave 2 to the neighbor and 2 to the repairman, then bought 5 more apples and ate 1, how many apples do I have left?
Few-shot prompting leverages the model's ability to generalize from limited examples (shots) and perform tasks with minimal explicit instruction. This technique is particularly useful in scenarios where acquiring large labeled datasets is impractical. It is versatile, adapting to a wide range of tasks and is easy to implement: you simply provide a brief explanation of the task along with a small set of input-output pairs as examples. One of the most challenging part is selecting appropriate examples because they are crucial for the model to accurately infer the task's structure and desired output format.
Exemple of Few-Shot Prompting (here it is a 1-shot example)
You are a 3rd grade student tasked with answering math problems in 1 line.
User: Lily has 12 apples. She wants to give an equal number of apples to her 3 friends. How many apples will each friend get
Assistant: 12 ÷ 3 = 4
User: If I bought 10 apples, gave 2 to the neighbor and 2 to the repairman, then bought 5 more apples and ate 1, how many apples do I have left?
For multi-label classification tasks, the minimal required output is a list of predicted labels. Few-shot prompting may involve a larger input token volume when incorporating numerous examples, but ultimately results in fewer tokens in the output by ensuring a concise and easily exploitable format. By focusing on a controlled output format, this approach offers an economical solution, as four words in the input cost the same as one word in the output.
For scenarios where budget and latency are not a problem Chain of Thoughts or Tree of Thoughts coupled with a well structured prompt and answer can also be a viable alternative.
Rate Limiting for API Calls
In scenarios where APIs impose limits on the number of requests that can be made within a specific timeframe, implementing a rate limiter becomes crucial. This ensures that applications stay within acceptable usage boundaries and prevent overwhelming the API provider with excessive requests. The ratelimit package simplifies this process by providing decorators that seamlessly integrate rate limiting into your Python functions.
Lets break down how it works:
from openai import OpenAI
from ratelimit import limits, sleep_and_retry
RATE_LIMIT_PERIOD = 60 # 60 seconds (1 minute)
RATE_LIMIT_CALLS = 50 # 50 calls per minute
def get_client():
client = OpenAI(api_key=API_KEY)
return client
@sleep_and_retry
@limits(calls=RATE_LIMIT_CALLS, period=RATE_LIMIT_PERIOD)
def get_chat_completion(messages):
client = get_client()
chat_completion = client.chat.completions.create(
model=MODEL_NAME,
messages=messages,
stream=False,
temperature=0,
seed=424242
)
return chat_completion
RATE_LIMIT_PERIOD specifies the duration of the rate limiting window in seconds.
RATE_LIMIT_CALLS indicates the maximum number of API calls allowed within the defined period.
@limits(calls=RATE_LIMIT_CALLS, period=RATE_LIMIT_PERIOD) decorator enforces the rate limit on the get_chat_completion function.
@sleep_and_retry decorator wraps around the rate-limited function. When the rate limit is exceeded, it handles the excess calls by delaying and retrying them once the current rate-limiting window expires.
In our example, get_chat_completion is a function that interacts with OpenAI's chat API (client.chat.completions.create). If the function is called more than 50 times within a minute, the sleep_and_retry decorator ensures that the excess calls are delayed until the rate-limiting period resets.
By adhering to rate limits, you can ensure that your application interacts responsibly with APIs, avoiding service interruptions and potential outages.
A Multi-label Classifier with Few-Shot Prompting and OpenAI API
The following example presents how to make a multi-label classifier that tags short pieces of text. The classifier can select zero to many categories from 'sports', 'politics', 'economy', and 'entertainment':
def intersection(lst1, lst2):
return list(set(lst1) & set(lst2))
def get_labels_from_chat_completion(
chat_completion,
labels_wanted: list[str] = None,
labels_prefix: str = None
) -> list[str]:
if len(chat_completion.choices) == 0 :
return []
chat_completion_message_content = chat_completion.choices[0].message.content
if labels_prefix is not None:
chat_completion_message_content = chat_completion_message_content.replace(labels_prefix, "")
labels_str = chat_completion_message_content.strip()
if len(labels_str) == 0:
return []
labels = labels_str.split(',')
cleaned_labels = [label.strip() for label in labels]
if labels_wanted is not None:
cleaned_labels = intersection(labels_wanted, cleaned_labels)
cleaned_labels.sort()
return cleaned_labels
def multi_label_llm(content_txt: str):
if len(content_txt) == 0:
return []
messages = [
{
"role": "system",
"content": "You are a multi-label classifier tasked with identifying appropriate tags for a given text. Return the tags as a simple list separated by commas. If no tags apply, return nothing. The available tags are: 'sports', 'politics', 'economy', and 'entertainment'. Always consider the context of the text to determine the relevance of each tag."
},
{
"role": "user",
"content": "Text: 'Election debate highlights key economic policies.'"
},
{
"role": "assistant",
"content": "Tags:politics,economy"
},
{
"role": "user",
"content": "Text: 'AI will take on the world.'"
},
{
"role": "assistant",
"content": "Tags:"
}
]
messages.append(
{
"role":"user",
"content": "Text: '{content_txt}'"
}
)
chat_completion = get_chat_completion(messages)
labels = get_labels_from_chat_completion(chat_completion, labels_wanted=['sports', 'politics', 'economy', 'entertainment'], labels_prefix='Tags:')
return labels
multi_label_llm(
"Stock market hits new highs amid economic boom."
)
intersection compute the intersection of two lists, i.e. the elements that are common to both lists.
get_labels_from_chat_completion processes the chat completion response to extract and clean labels. It handles a possible response prefix, splits the labels from the text into an array, trims whitespace, filters out unwanted labels and sorts the final list of labels.
multi_label_llm processes a text through a LLM that predicts which labels apply to the text. The context and goal of the task are explained in the system prompt. Two pairs of examples are added to the messages stack to help the model understand the format of the answer and the subtleties of the task. The text we want to process is provided as the last element of the messages stack, which is then sent to the LLM. Finally, the answer is formatted to return an array of strings.
Note that with Few-Shot Prompting, adding more labels to the classification task can reduce precision. The language model might struggle to accurately identify the most relevant labels when more options are available, potentially leading to less precise tagging. If this is the case and your labels allow it, a good workaround is to perform consecutive calls: first, a general one to determine broad categories, which can then trigger more specialized labeling calls. It's also worth experimenting with more complex techniques that are less affected by this issue.
Conclusion
Leveraging Large Language Models (LLMs) for Multi-Label Classification in text analysis presents a powerful alternative to traditional Natural Language Processing (NLP) techniques.
The capabilities of LLMs to handle complex and nuanced data make them highly suitable for tasks where multiple labels are needed. With their user-friendly APIs, LLMs offer ease of use, cost-efficiency, and high performance, enabling rapid deployment and effective handling of real-world data challenges.
By incorporating advanced techniques like few-shot prompting, chain of thought, or tree of thoughts, users can further enhance the precision and applicability of these models, ensuring robust and scalable solutions for diverse text analysis needs.
Regular evaluation and prompt refinement are key to maintaining the accuracy and relevance of the model in production environments, ultimately driving better decision-making and strategic insights.
Annexe: Multi Label Classification Metrics Overview
Subset Accuracy score
The Subset Accuracy Score, also known as the “exact match ratio”, is the strictest measure. It requires that each set of predicted labels for a sample corresponds exactly to the set of actual labels.
The Accuracy is computed for every sample then averaged on the whole set. The more the better. Ranging from 0 to 1.
Subset Zero One Loss
Zero One Loss is similar to subset accuracy, but rather than being a score, it's a loss where 0 means no error and 1 means at least one error in the prediction.
The Loss is then averaged on the whole set. The less the better. Ranging from 0 to 1.
Hamming Loss
Hamming Loss measures the fraction of labels that are incorrectly predicted, i.e. the fraction of times the wrong label is predicted, independently of the other labels.
The Loss is then averaged on the whole set. The less the better. Ranging from 0 to 1.
Precision
Precision measures the proportion of positive identifications that were actually correct. It is the score to prioritize if we want to avoid false positives: the precision is intuitively the ability of the classifier not to label as positive a sample that is negative.
For multi-label classification, multiple strategies for averaging are available:
micro: Calculate metric globally by counting the total true positives, false negatives and false positives.macro: Calculate metric for each label, and find their unweighted mean. This does not take label imbalance into account.weighted: Calculate metric for each label, and find their average weighted by support (the number of true instances for each label). This does handle well label imbalancesamples: Calculate metric for each sample, and find their unweighted mean. In binary or multiclass setting: this strategy is equivalent to the accuracy score, but not in multilabel settings where the classifier allow samples to have multiple labels. This strategy is valuable if we want to understand how well the model captures the correct labels for each data point.
The more the better. Precision is ranging from 0 to 1.
Recall
Recall measures the proportion of real positives that have been correctly identified. It is the score to prioritize if we want to avoid false negatives: the recall is intuitively the ability of the classifier to find all the positive samples.
For multi-label classification, the same multiple strategies as Precisions are available for averaging (micro, macro, weighted, samples).
The more the better. Recall is ranging from 0 to 1.
F1-score
F1-score is the harmonic mean of Precision and Recall. It combines both metrics. The relative contribution of precision and recall to the F1 score are equal: it is the score to prioritize if we want to avoid both false positives and false negatives.
For multi-label classification, the same multiple strategies as Precisions are available for averaging (micro, macro, weighted, samples).
The more the better. F1-Score is ranging from 0 to 1.
Jaccard Score
The Jaccard Score (or Index) measures the similarity between two sets of labels, defined as the size of the intersection divided by the size of the union of the sets of labels.
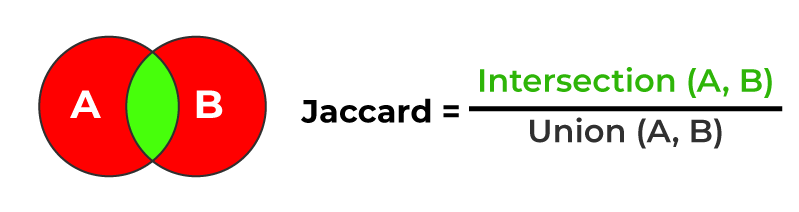
For multi-label classification, the same multiple strategies as Precisions are available for averaging (micro, macro, weighted, samples).
The more the better. Jaccard Score is ranging from 0 to 1.
Sources
https://en.wikipedia.org/wiki/Multi-label_classification
https://scikit-learn.org/stable/modules/model_evaluation.html#multilabel-ranking-metrics
https://en.wikipedia.org/wiki/Jaccard_index
https://scikit-learn.org/stable/modules/multiclass.html#multilabel-classification
https://scikit-learn.org/stable/modules/model_evaluation.html#classification-metrics
https://platform.openai.com/docs/guides/text-generation/chat-completions-api
https://platform.openai.com/docs/guides/text-generation/reproducible-outputs
https://platform.openai.com/docs/api-reference/chat/create#chat-create-seed